Från Jupyter Notebooks till Produktion: MLOps Workshop på Tech Borås
Den 23 september genomförde jag den tredje och avslutande workshopen i AI Lab-serien på Högskolan i Borås. Den här gången tacklade vi gapet mellan experimentering och produktion. Problemet med att “kasta det över staketet” som dödar många ML-projekt.

Problemet med utvecklingsmiljön
De flesta ML-projekt börjar i Jupyter notebooks. Du laddar in data, utforskar den, tränar en modell, validerar den och kallar det klart. Det fungerar för experiment, men skapar ett problem: hela arbetsflödet lever på din laptop i en linjär, manuell process.
Det typiska data science arbetsflödet
- Dataanalys - Utforska och förstå ditt dataset
- Förbehandling - Rensa och transformera data
- Modellträning - Anpassa din modell till datan
- Modellvalidering - Kontrollera om den faktiskt fungerar
- Modellöverlämning - Hoppas att någon kan distribuera den
Varje steg körs manuellt. Ingen automation. Ingen versionering. Inget sätt att reproducera resultat tillförlitligt. När din modell presterar bra i validering så står du inför en fråga: hur får du in detta i produktion?
På ett litet företag hanterar en person allt från dataanalys till distribution. Överlämningen sker mellan olika roller som samma person har.
På mellan- och stora företag bygger data scientists modeller men har svårt att lämna över dem till ingenjörsteam. Modellen som fungerade perfekt i en notebook misslyckas i produktion, eller ännu värre, blir oanvända eftersom det är för svårt med deployment.
MLOps-metoder byggda på CI/CD-principer löser detta genom att eliminera överlämningen helt och hållet. Istället för att skicka artefakter mellan team eller roller bygger du automatiserade pipelines som flyttar kod från experiment till produktion. Samma pipeline som tränar din modell distribuerar den också.
“Kasta över staketet” anti-mönstret
När organisationer försöker skala sitt ML-arbete stöter de på en vägg. Bokstavligt talat.
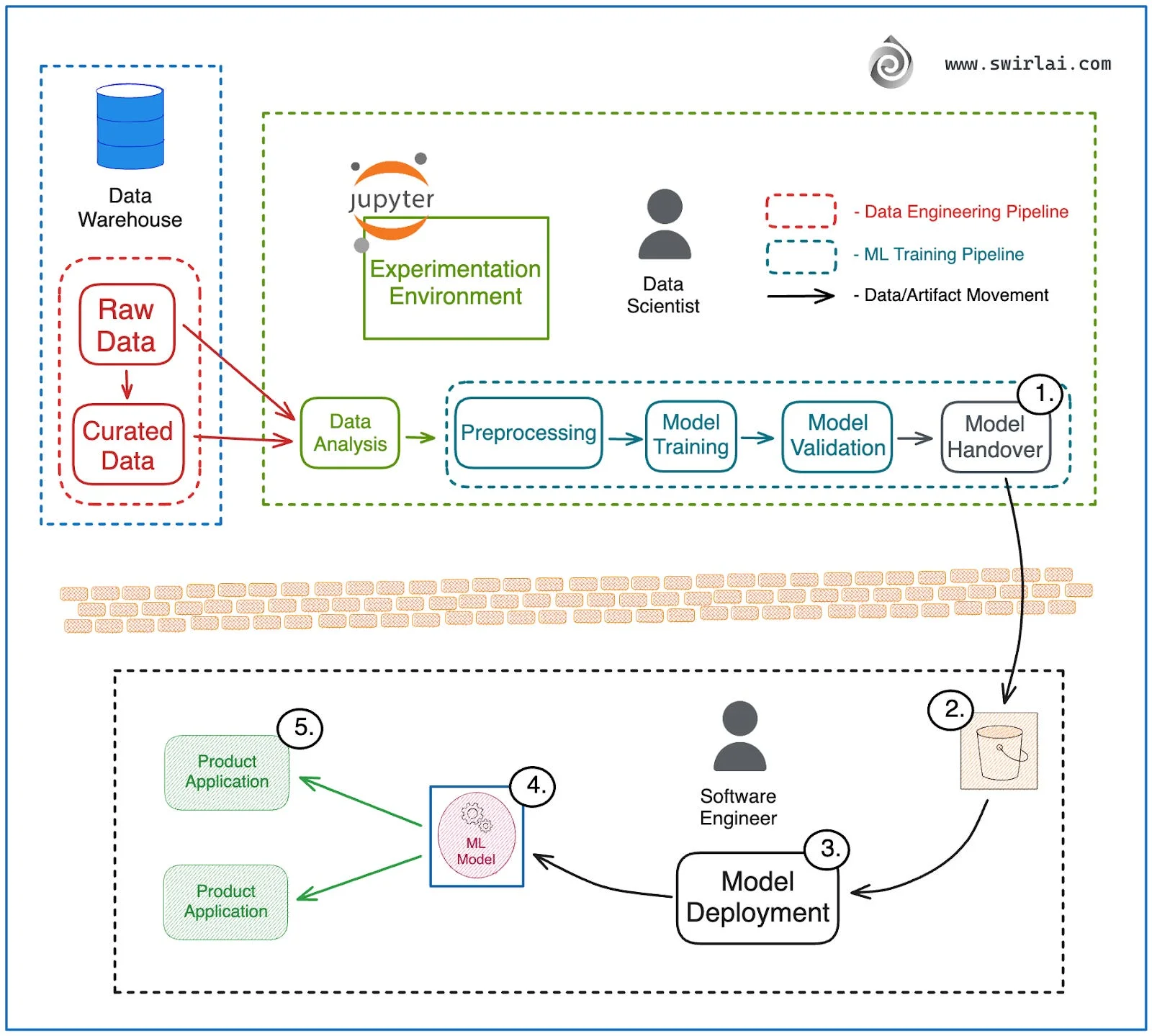
Titta på diagrammet ovan. Till vänster arbetar data scientist i Jupyter, kopplad till datalagret. De analyserar data, förbehandlar den, tränar en modell, validerar den. I slutet av denna pipeline sitter Modellöverlämning (steg 1).
Sen kommer väggen. Tegelväggen i mitten representerar organisatorisk separation. Modellartefakten dumpas i en bucket (steg 2) och skickas över till andra sidan. Ingen träningskontext. Ingen förbehandlingskod. Inga valideringsmått. Bara en picklad modellfil och en massa hopp.
På andra sidan tar mjukvaruingenjören emot denna artefakt (steg 3). De försöker distribuera (steg 4), packar in den i en container och exponerar den till produktapplikationer (steg 5). Sen slår verkligheten till.
Modellen som uppnådde 95% noggrannhet i notebooken får 60% i produktion. Varför?
- Olika datafördelningar: Träning använde förra månadens data, produktion ser dagens data
- Saknad förbehandling: Notebooken hade 10 celler med datarensning som aldrig dokumenterades
- Beroende-missmatchningar: Modellen tränad med scikit-learn 1.4, produktion kör 1.0
- Ingen övervakning: När noggrannheten sjunker märker ingen det på flera veckor eller månader
Det här arbetsflödet går sönder eftersom det behandlar modellutveckling och distribution som separata problem. Data scientist optimerar för noggrannhet i experiment. Ingenjören optimerar för tillförlitlighet i produktion. Dessa mål konfliktar när det finns en vägg mellan dem.
Dokumentation fixar inte detta. READMEs blir föråldrade. Kommentarer ignoreras. Vad du behöver är delad infrastruktur som båda rollerna interagerar med under sitt arbete.
MLOps-lösningen: produktionsarkitektur
Lösningen bryggar över väggen med hjälp av delad infrastruktur. Istället för två isolerade miljöer bygger du automatiserade pipelines som kopplar samman data, träning och distribution.
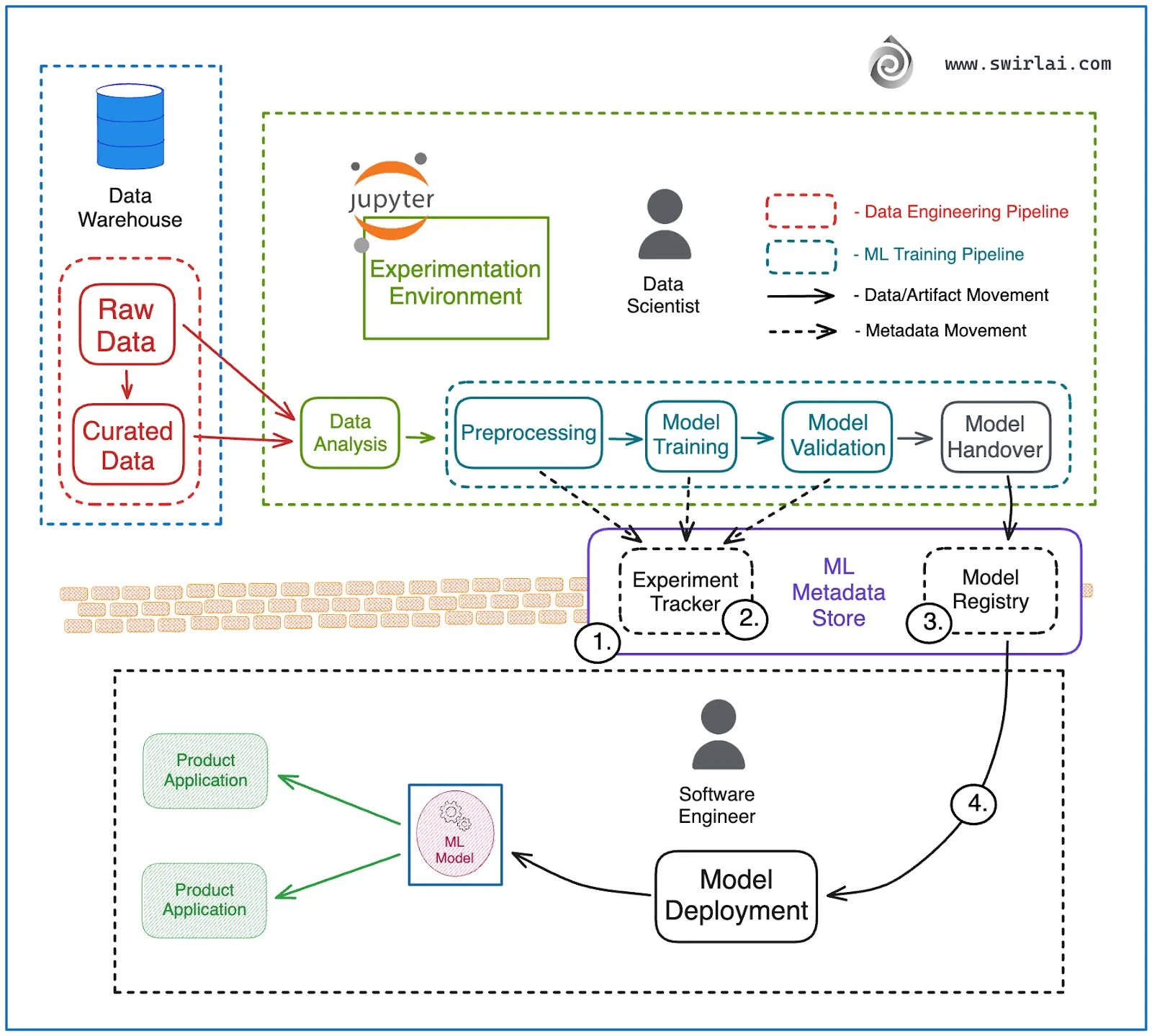
Diagrammet visar en produktions-ML-miljö. Tre automatiserade pipelines ersätter manuella överlämningar: Data Engineering (lager till kurerad data), ML Training (förbehandling genom validering) och Deployment (register till produktion).
I centrum sitter en metadata-hubb med tre komponenter:
- Experiment Tracker: Loggar mätvärden och parametrar från varje träningskörning
- ML Metadata Store: Spårar dataursprung och artefaktrelationer
- Model Registry: Lagrar versionshanterade modeller redo för distribution
En orkestrator som Airflow kör dessa pipelines enligt scheman eller triggers och skapar en Continuous Training-loop där modeller omtränas automatiskt när data förändras.
Väggen är delvis besegrad. Både data scientists och utvecklare nyttjar samma modellregister och metadata store. Modellen som distribueras är exakt den modell som validerades, med full versionering.
Bygga pipelinen: MLflow + Airflow
Workshopen på Tech Borås omsatte denna teori till praktik. Deltagarna fick testa på att bygga en komplett MLOps-pipeline med MLflow för spårning och Airflow för orkestrering, allt körande lokalt på sina laptops.
Tech-stacken
- MLflow: Experimentspårning, metadata store och modellregister
- Airflow: Pipeline-orkestrering med en Directed Acyclic Graph (DAG)
- uv: Snabb Python-pakethanterare för beroendehantering
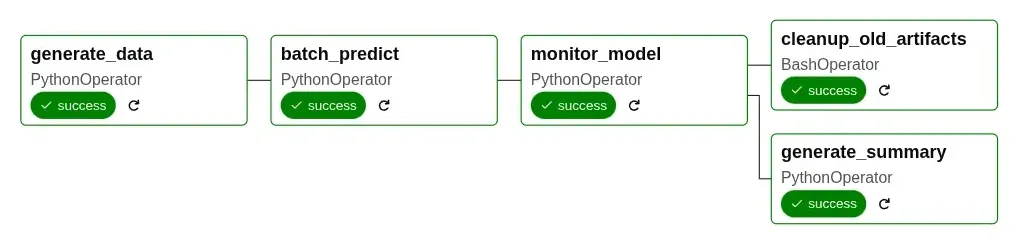
DAG-strukturen
Diagrammet visar fem uppgifter som körs i sekvens och parallellt:
- generate_data (PythonOperator): Simulerar ny data från ett lager
- batch_predict (PythonOperator): Laddar den registrerade modellen och gör prediktioner
- monitor_model (PythonOperator): Kontrollerar prediktionskvalitet och loggar mätvärden till MLflow
- Efter övervakning körs två uppgifter parallellt:
- cleanup_old_artifacts (BashOperator): Tar bort gamla filer
- generate_summary (PythonOperator): Skapar prestandarapporter
DAG:en interagerar med MLflows modellregister för att hämta den senaste produktionsmodellen och loggar mätartal med hjälp av experimentspåraren.
Installation och uppsättning
Hela exempel koden finns tillgänglig på github.com/krjoha/ai-lab-mlops
. Till workshopen använde vi uv, en snabb Python-pakethanterare skriven i Rust som hanterar beroendeupplösning och virtuella miljöer. Den är betydligt snabbare än pip och skapar reproducerbara miljöer. Både MLflow och Airflow körs som lokala tjänster:
- MLflow tillhandahåller webbgränssnittet för experimentspårning och modellregister på
http://localhost:5000 - Medan Airflow kör schemaläggaren och webbgränssnittet för DAG-hantering på
http://localhost:8080.
| |
Efter att ha startat Airflow, hitta användarnamn och lösenord i terminalutskriften eller i airflow/simple_auth_manager_passwords.json.generated.
Träning och registrering av en modell
Kör träningsskriptet för att skapa en initial modellen:
| |
Du kan se den lagrade och versionshanterade modellen i MLflow-gränssnittet på http://localhost:5000/#/experiments. Efter att ha skapat en modell och lagrat den i MLflow-registret kan du gå till Airflow-gränssnittet på http://localhost:8080 och köra prediktions-DAG/pipelinen därifrån.
Här bygger vi en sentimentklassificeringsmodell med scikit-learns Pipeline för att kedja ihop en TF-IDF-vektoriserare med logistisk regression. Kärnlogiken för träning finns att beskåda på tasks/train_model.py
, här följer ett urklipp av koden:
| |
Det som är viktigt: mlflow.register_model() placerar den tränade modellen i ett centralt register som steg nedströms i vår pipeline kan ladda in via dess namn, inte via någon filsökväg till nåt picklat object. Denna separation mellan träning och distribution betyder att data scientists kan registrera flera modellversioner, och utvecklare kan alltid ladda den senaste versionen utan att behöva röra träningskoden.
Modellövervakning
Vårt övervakningssteg analyserar prediktionstrender över tid genom att nyttja MLflows experimentspårning. Istället för att kontrollera ett enda mätartal tittar den på mönster över flera DAG-körningar för att upptäcka försämring och förändringar tidigt (se tasks/monitor_model.py
för fullständig implementation):
| |
Detta skapar en återkopplingsloop: prediktioner genererar mätvärden, övervakningssteget analyserar dessa mätvärden över tid, och varningar triggas när mönster indikerar problem. Allt spåras i MLflow.
Workshopen omsatte MLOps-teori till praktik. Deltagarna byggde kompletta pipelines med MLflow-spårning, Airflow-orkestrering och automatiserad övervakning körande på sina egna laptops. Samma arkitektur som hanterade sentimentklassificering i workshopen skalar till bedrägeridetektering, rekommendationssystem eller efterfrågeprognoser i produktion.
Det som får detta tillvägagångssätt att fungera är att eliminera överlämningen. När data scientists och ingenjörer båda interagerar med ett delat modellregister försvinner problemet med att “kasta det över staketet”. Automatiserade pipelines fångar problem under utveckling, inte i produktion. Övervakningsteg spårar trender över körningarna istället för att vänta på att användare (kanske) rapporterar ett problem.
MLOps & AI-konsult i Borås
Detta var den tredje workshopen i AI Lab-serien på Högskolan i Borås, fokuserad på praktisk MLOps för utvecklare och ingenjörer. Jag tillhandahåller AI- och data engineering konsulting för företag i Borås och i hela Sverige. Om du behöver hjälp med att implementera MLOps-infrastruktur, bygga ML-pipelines eller flytta modeller från experiment till produktion, hör av dig.